책보다가.. 많이 사용할 일이없던 여러 키워드를 발견했었다. 이제서야 정리를 하다니 
그중 하나가 volatile 키워드. 처음에 한두개 글들을 보면서 이해가 되지 않아 몇번이고 봤었다.
본것중에 제일 이해가 잘가는 곳의 내용을 퍼와서 정리해보았다.
1. 아래의 내용은 블로그 http://kwanseob.blogspot.kr/2012/08/java-volatile.html 에서 가저온 것입니다.
--------------------------------------------------------------------------------------------------------------------------------------------------------
원 글 Java's Volatile Keyword 을 참고하여 번역하였습니다.
Java volatile 키워드는 자바 변수를 "메인 메모리에 저장 할" 표식으로 사용합니다. 좀 더 정확하게 말하자면 모든volatile 변수를 읽어 들일 때 CPU 캐시가 아니라 컴퓨터의 메인 메모리로 부터 읽어들입니다. 그리고 volatile 변수를 쓸 때에도(write) CPU 캐시가 아닌 메인 메모리에 기록합니다.
java 5 이래로 volatile 키워드는 volatile 변수들을 메인 메모리로 부터 읽고 쓰는걸 것 보다 더 큰 의미를 가지는데 이는 곧 다시 설명 하겠습니다.
Java volatile은 변수의 가시성(Visibility)을 보장한다.
Java volatile 키워드는 여러개의 쓰래드들 에서 사용되는 변수의 변화(값의 변화) 에 대한 가시성의 보장합니다. 이 말이 좀 추상 적으로 느껴질 수 있는데 자세하게 설명하자면
non-volatile 변수들로 운영되는 멀티 쓰래드 어플리케이션에서 각 쓰래드들은 성능적이 이유로 메인 메모리로 부터 변수를 읽어 CPU 캐시에 복사하고 작업하게 됩니다. 만약 여러분의 컴퓨터에 하나 이상의 CPU로 구성되어 있고 각 쓰래드들이 서로 다른 CPU에서 실행 될수 있습니다. 이 말은 각 쓰래드들이 서로 다른 CPU들의 CPU 캐시에 값을 복사할 수 있다는 것으로 아래의 다이어그램이 이를 설명해주고 있습니다.
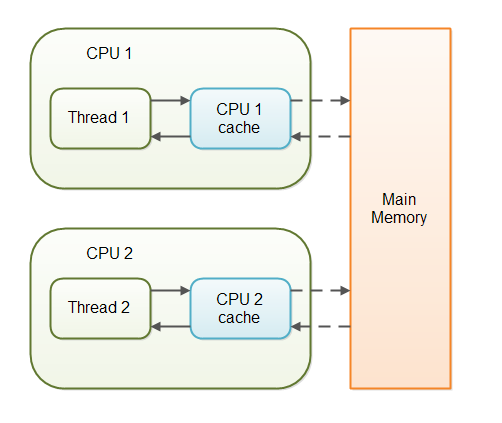
non-volatile 변수들은 어느 시점에 Java Virtual Machine(JVM)이 메인 메모리로 부터 데이터를 읽어 CPU 캐시로 읽어 들이거나 혹은 CPU 캐시들에서 메인 메모리로 데이터를 쓰는지(write) 보장해 줄 수 없습니다. 이럴 경우 어떤 문제가 발생 할 수 있는지 예를 들어 보겠습니다.
두 개 혹은 그 이상의 쓰래드가 접근하고 사용하는 공용 오브젝트에 counter 라는 변수가 아래와 같이 선언된 상황을 가정합니다 :
public class SharedObject {
public int counter = 0;
}
1번 쓰래드가 공유 오브젝트의 counter 값인 0 을 CPU 캐시로 읽어 갑니다. 그리고 1 로 증가 시킨 후 메인 메모리에는 아직 쓰지 않았습니다. 2번 쓰래드가 같은 공유 오브젝트의 counter 값을 메인 메로리로 부터 읽어 가는데 이 때 아직 값은 0 입니다. 그리고 이를 CPU 캐시에 복사하고 2번 쓰래드 역시 이 값을 1로 증가 시키고 역시 메인 메모리로 쓰지 않았습니다. 이 경우 1번과 2번 쓰래드의 동기화(sync)가 깨진 상태입니다. 실제 공유 오브젝트의 counter값은 실질적으로 2 여야 하는데 각 쓰래드에서 CPU 캐시들에 1 로 기록한 상태입니다. 메인 메모리에는 아직 0 인 상태입니다. 쓰래들이 공유 counter 변수를 메인 메모리로 다시 쓸 경우 결국 이 값은 잘못 된 값입니다.
공유 counter 변수에 volatile을 선언함으로써 JVM은 해당 변수에 대한 모든 읽기 연산을 항상 메인 메모리에서 부터 읽어가도록 보장해 줍니다. 그리고 변수에 대한 모든 write 역시 항상 메인 메모리에 기록되도록 해 줍니다. volatile 선언은 다음과 같이 할 수 있습니다.
public class SharedObject {
public volatile int counter = 0;
}
멀티 쓰래드에서 접근하는 변수의 가장 최근에 기록된 값을 보기(see)때문에 변수에 간단하게 volatile을 선언 해주는 것이 충분한 경우도 있습니다. 어떤 경우에 volatile 선언해야 하는지 좀 더 뒤에 살펴보겠습니다.
이번에도 두 개의 쓰래드에서 같은 변수를 읽고 쓰는 상황을 가정하겠습니다. 변수에 간단하게 volatile 을 선언하는 것으로 충분하지 않은 상황으로 1번 쓰래드에서 counter 변수 값 0을 CPU 1의 CPU 레지스터로 읽고, 이와 동시에(또는 바로 이어서) 2번 쓰래드에서 counter 변수 1을 CPU 2의 CPU 레지스터에 읽었습니다. 두 쓰래드들이 메인 메모리로 부터 바로 변수의 값을 읽었습니다. 이제 두 변수들에 값을 증가시켜 메인 메모리로 다시 쓰기 연산이 실행됩니다. 두 레지스터에서 counter의 값을 1로 증가시켰기 때문에 메인 메모리로 기록할 때 1로 기록합니다. 실제로는 두번의 증감으로 값이 2 가 되어야 합니다.
멀티 쓰래드의 문제점은 다른 쓰래드에서 메인 메모리로 아직 기록하지 않은 값을 보지 못했기 때문입니다. 이를 "가시성" 문제라고 불립니다. 한 쓰래드에서의 업데이트는 다른 쓰래드에서는 볼수 없습니다.
The Java volatile Guarantee
Java 5의 volatile 키워드는 단순히 변수를 메인 메모리로 부터 읽고 쓰는것을 이상울 보장(guarantees) 해 주는데 실제로 volatile 키워드가 보장해주는 것은 :
만약 쓰래드 A가 volatile 변수에 쓰기 작업을 하고 쓰래드 B가 바로 직후에 같은 volatile 변수를 읽을 경우, volatile 변수를 쓰기 직전에 모든 변수를 쓰래드 A에서 볼 수(visible) 있습니다. 쓰래드 B 역시 볼 수 있습니다.
volatile 변수들의 읽고 쓰기 연산은 JVM에 의해 재배치(reorder) 되지 않습니다.(JVM은 프로그램이 reordering에 의해 동작이 바뀌지 않는 한 성능상의 이유로 JVM이 instructions을 reorder 할 수 있습니다.) volatile 이전, 이후의 명령(Instructions)들은 재배치 될 수 있습니다. 하지만 volatile 읽기 혹은 쓰기는 이 연산들과 섞이지 않습니다. volatile 변수에 대한 읽기 혹은 쓰기 연산 뒤에 실행되는 연산들은 volatile 읽기/쓰기 작업 이후에 실행됩니다.
아래 예제를 보면 :
Thread A:
sharedObject.nonVolatile = 123;
sharedObject.counter = sharedObject.counter + 1;
Thread B:
int counter = sharedObject.counter;
int nonVolatile = sharedObject.nonVolatile;
쓰래드 A가 volatile인 sharedObject.counter에 쓰기 연산 전에 sharedObject.nonVolatile non-volatile 변수에 기록합니다. 그러면 sharedObject.nonVolatile과 sharedObject.counter 두 변수는 메인 메모리에 기록 됩니다.
왜냐하면 쓰래드 B가 volatile sharedObject.counter를 읽으면서 시작했기 때문에 두 sharedObject.counter와 sharedObject.nonVolatile 변수는 메인 메모리로 부터 읽었기 때문입니다.
non-volatile 변수의 읽기와 쓰기는 volatile 변수의 읽기/쓰기 전과 후에 위치하면 재배치(reordered) 되지 않습니다.
언제 volatile이 적합한가?
앞서 언급하였든 두 쓰래드가 공유 변수에 대한 읽기와 쓰기 연산이 있을 경우 volatile 키워드로는 충분하지 않습니다. 이 경우 synchronization 를 통해 변수의 읽기 쓰기 연산의 원자성(atomic)을 보장해 줘야합니다.
하지만 한 쓰래드에서 volatile 변수의 값을 읽고 쓰고, 다른 쓰래드에서는 오직 변수 값을 읽기만 할 경우, 그러면 읽는 쓰래드에서는 volatile 변수의 가장 최근에 쓰여진 값을 보는 것을 보장할 수 있습니다. volatile 없이는 이를 보장해 줄 수 없습니다.
volatile 의 성능 고려사항
volatile 변수에 대한 읽기와 쓰기는 변수를 메인 메모리로 부터 읽거나 쓰게 됩니다. 메인 메모리에 읽고 쓰는것은 CPU 캐시보다 더 비싸다고 할 수 있습니다. 또한 volatile 변수는 성능을 개선 기법인 명령(instruction)들의 재배치를 방지하기 때문에 변수의 가시성을 강제할 필요가 있는 경우에만 volatile 변수를 사용하는 것이 좋습니다.
2. 아래의 내용은 블로그 http://tomowind.egloos.com/4571673 에서 가저온 것입니다.
--------------------------------------------------------------------------------------------------------------------------------------------------------
volatile이란 단어의 뜻은 "변덕스러운"이다. 다시 말하자면 "자주 변할 수 있다"로 생각할 수 있다. 프로그래밍 언어에서는 정의는 언어와 버전마다 다르지만, 대충은 "자주 변할 수 있는 놈이니 있는 그대로 잘 가져다써"정도로 생각을 하면 되겠다. 조금 더 엄밀히 정의를 하자면, (1) 특정 최적화에 주의해라, (2) 멀티 쓰레드 환경에서 주의해라, 정도의 의미를 준다고 보면 된다.
Java에서는 어떤 의미를 가질까? volatile을 사용한 것과 하지 않은것의 차이는 뭘까? volatile의 버전마다의 차이는 뭘까? synchronization과 volatile의 차이는 뭘까? 이 의문들에 대해서 정리한 것은 다음과 같다.
- volatile을 사용하지 않은 변수: 마구 최적화가 될 수 있다. 재배치(reordering)이 될 수있고, 실행중 값이 캐쉬에 있을 수 있다.
- volatile을 사용한 변수 (1.5미만): 그 변수 자체에 대해서는 최신의 값이 읽히거나 쓰여진다.
- volatile을 사용한 변수 (1.5이상): 변수 접근까지에 대해 모든 변수들의 상황이 업데이트 되고, 변수가 업데이트된다.
- synchronziation을 사용한 연산: synch블락 전까지의 모든 연산이 업데이트 되고, synch안의 연산이 업데이트된다.
무슨 말인지 전혀 모를 수 있다. 앞으로 예제를 들면서 이해를 시켜보도록 노력하겠다.
첫 예제는 Jeremy의 블로그에서 가져온다. 나는 위의 4가지의 경우를 완전히 정립하지 못한 상태에서 봐서 이 예제의 설명이 모호했다고 느꼈다. 블로그의 설명을 보고 내 설명을 보면 이해가 더 될지도 모르겠다.
Thread 1
1: answer = 42;
2: ready = true;
Thread 2
3: if (ready)
4: print (answer);
예제1. 1 -> 2 -> 3 -> 4 순서로 프로그램이 진행된다. ready는 애초에 false다.
첫번째로 ready를 volatile을 걸지 않았다고 해보자. 그럼, answer와 ready가 마구 최적화가 된다. 또한, 그들이 실행시간에 캐쉬된 값들이 바로바로 메인 메모리에 업데이트 되지 않을 수 있다. 만약, 2번 문장의 ready값이 실행이 된 후에 캐쉬만 업데이트를 한 후, 3번이 실행되었다면, 3에서는 ready를 false로 읽었을 수가 있다. --> 에러
두번째로 ready에 volatile을 걸었다고 하자 (버전 1.5 미만). 그럼, ready의 값은 읽혀지거나 쓰여질 때마다 바로 업데이트 된다. 즉, 2번 문장이 실행된 후에 메인 메모리의 ready는 true라고 쓰여진다. 따라서, 3번 문장이 실행될때에 ready는 메인 메모리에서 값을 읽어와서 4번을 안정적으로 실행을 한다. 하지만, answer는 volatile이 정의되지 않았다면 값이 정확히 전해지는 것을 보장할 수가 없다. 4번 문장이 42말고 그 전의 값을 "읽을수도 있다". ---> 에러
세번째로 ready에 volatile을 걸었다고 하자 (버전 1.5 이상). 그럼, ready의 값이 읽혀지거나 쓰여질 때마다 그 때까지의 쓰레드의 모든 상태가 없데이트 된다. 즉, 2에서 ready값이 메인 메모리로 업데이트 되면서, 같은 쓰레드에 있는 answer도 메인 메모리에 업데이트가 된다! 그래서, 3번의 if문은 당연히 참이 되고, 4번에서 answer값도 42를 읽게 된다. --> 성공
이제 대충 감이 잡히는가? 그럼 예제를 하나 더 보자. 그 유명한 Double-Checked Locking 문제이다.
class Foo {
private Helper helper = null;
public Helper getHelper() {
1: if (helper == null)
2: helper = new Helper();
3: return helper;
}
}
코드 1. Single-thread 버전의 singleton pattern (Multi에서 안돌아).
이 글을 읽는 사람들이 singleton 디자인 패턴은 다 안다고 가정을 하고 설명을 하겠다. 위의 코드는 singleton 패턴을 사용한 코드다. 쓰레드가 하나일 때에는 잘 동작을 한다. 하지만, 쓰레드가 여럿일 때에는 문제가 생긴다. 예를들어, 다음과 같은 순서를 생각해봐라.
- Thread 1이 Statement 1접근 (if --> true)
- Thread 2가 Statement 1접근 (if --> true)
- Thread 1이 Statement 2접근하여 할당
- Thread 2가 Statement 2접근하여 할당 ---> 에러!
class Foo {
private Helper helper = null;
public synchronized Helper getHelper() {
if (helper == null)
helper = new Helper();
return helper;
}
}
코드 2. Multi-thread 버전의 singleton pattern (너무 비쌈).
코드 2는 완벽히 잘 동작한다. 하지만. 문제는 synchronization이 너무 비싸다는 데에 있다. 우리는 저렇게 비싼걸 접근시 매번 불러주기는 싫다. 그래서, 아래처럼 double checked locking이라는 요상한 방법을 고안해낸다.
class Foo {
private Helper helper = null;
public Helper getHelper() {
if (helper == null)
synchronized(this) {
if (helper == null)
helper = new Helper();
}
return helper;
}
}
코드 3. Double Checked Locking (문제있음).
우아, 똑똑하다. 왠지 잘 동작할 것 같은 코드다. 만약 할당 안된 두 개의 쓰레드가 접근을 하면 멈춰서 하나만 할당을 해주고 넘겨준다. 당연히 잘 되야 하지 않는가? 근데, 이것도 잘 안된다. 문제는 아래처럼 컴파일 될 때이다.
class Foo {
private Helper helper = null;
public Helper getHelper() {
1. if (helper == null)
2. synchronized(this) {
3. if (helper == null) {
4. some_space = allocate space for Helper object;
5. helper = some_space;
6. create a real object in some_space;
}
return helper;
}
}
예제 2. Double Checked Locking (상세하게).
머신 코드단에서는 최적화에 의해 저렇게 재배치(reordering)이 될 수 있다. 그러면 이제 어떤 시나리오가 문제가 되냐?
1. Thread1이 1~5까지 실행. 즉, helper는 null은 아니지만, 완전한 객체는 아님.
2. Thread2가 1을 실행후에 helper가 생성되었다고 인지.
3. Thread2가 getHelper()함수를 탈출하고, 외부에서 helper를 이용해서 무언가를 하려함 --> 에러!
진짜 생각지도 못한 low-level버그가 생기는 것이다. 이 버그는 volatile을 안쓰면 당연히 생기고, helper를 volatile로 선언해도 version에 따라 차이가 있다. 왜 그런가?
버전 1.5 미만일 경우에는 접근에서 그 변수 자체에만 업데이트를 해주도록 되어있다. 즉, some_space는 상관없이 5번 문장을 실행한 후에 helper가 가진 값이 some_space라고 메인 메모리에 써주기만 하면 되는 것이다. 즉, 위의 시나리오가 그냥 그대로 진행될 수가 있다.
버전 1.5 이상일 경우에는 그 변수를 포함한 모든 값이 업데이트가 된다고 했다. 즉, 코드 3에서 new Helper() 가 다 만들어지고 그게 업데이트가 되고 helper에 그 값이 들어가야 하는 것이다. 다시 말하면, 애초에 예제 2처럼 컴파일이 되지도 않는 다는 거다! 재배치 없이 컴파일이 되고, Helper()가 업데이트가 되고, 그게 helper에 써지고, helper가 메인 메모리에 업데이트가 되어 문제가 생길 소지가 없게 된다.
이렇게, 두 예제를 살펴봤다. 대충 volatile이 쓰면 어떻게 변하는지, 버전에 따른 변화가 어떤지 감이 잡힐꺼라고 생각을 한다.
마지막으로 volatile과 synchronization을 살펴보자. 아래의 코드가 이해를 도와줄 거라고 생각한다. i와 j를 보고 연산에 어떤 차이가 있을지 생각해봐라. 어느 변수가 멀티쓰레드 환경에서 문제가 될까?
1. volatile int i;
2. i++;
3. int j;
4. synchronized { j++; }
코드 4. volatile vs synchronized
대략 감이 잡힌다면 정말 센스 만점인 사람이다. 답은 i가 문제가 될 수 있고, j는 괜찮다는 거다. 왜냐면 i++ 이란 문장은 read i to temp; add temp 1 ; save temp to i; 라는 세개의 문장으로 나뉘어지기 때문이다. 따라서, read나 write하나만 완벽히 실행되도록 도와주는 volatile은 2번 문장이 3개로 나뉘어 질 경우에 다른 쓰레드가 접근하면 문제가 생길 수가 있다. 하지만, synchronized는 그 블럭안에 모든 연산이 방해받지 않도록 보장해주기에 j는 제대로 업데이트가 된다.
이제 대략 감이 잡혔으면 한다. 다른 자료들에 나온 설명이 어려운 용어들을 써서 이해가 잘 안될수가 있는데, 내 글이 이해에 도움이 되길 바란다. 만약 이 글도 너무 어렵다면 리플을 남기면 최대한 노력해서 답변하겠다.
참고자료.
1. Volatile in wikipedia: 1.5 전후의 설명을 아래처럼 해놨다. 어려워 보이지만 내가 위에 써놓은 것과 같은 뜻이다.
- Java (모든 버전): volatile로 선언한 변수의 read, write에는 global ordering이 주어진다.
- Java 1.5 이후: volatile로 선언한 변수의 read, write마다 happens-before relationship이 성립이 된다.
4. The "Double-Checked Locking is Broken" Declaration: volatile보다는 double-checked locking에 대해서 제대로 나와있다. synchronized를 사용한 비싼 방법이나, volatile을 사용하는 방법 이외에도 재미있는 해결책이 많다.
--------------------------------------------------------------------------------------------------------------------------------------------------------
내용추가
동기화에 소요되는 자원낭비를 막기 위하여, 불러오고 저장하는(load & store) 단순한 작업을 하는 상황에서 동기화 설정을 생략하는 경우가 있다. 하지만 이것은 두 가지의 이유 때문에 위험할 수 있다. 첫 번째로, 64비트 값을 불러오거나 저장하는 작업은 원자성을 가진다고 확신할 수 없다. double이나 long형에 값을 대입하는 경우, 전체의 반(32비트)이 우선 대입된 후 다른 스레드에 의해 선점(preempted)될 수 있다. 그렇게 되면 나중에 수행되는 스레드는 예상과는 다른 값을 가지게 될 것이다. 게다가, 멀티프로세서 환경일 경우 각각의 프로세서는 주 메모리상에 있는 데이터와 분리된, 프로세서 자체 캐시(레지스터)를 사용하여 작업을 처리하는데, 이 두 데이터가 서로 다를 수 있다. synchronized 구문은 로컬(프로세서) 캐시가 주 메모리와 동일한 값을 가지도록 보장해준다. 동기화 되지 않은 메소드의 경우, 다른 스레드에 의해 공유자원이 변경되어도 인지하지 못한다.
volatile 구문은 이러한 문제를 해결하기 위하여 만들어졌다. volatile로 지정된 64비트 변수의 불러오기와 저장하기 작업은 원자성이 보장된다. 멀티프로세서의 경우에도 마찬가지로, 이 작업은 프로세서 캐시와의 동기화를 보장한다. 특정한 경우에 따라, 동기화 설정 대신 volatile 변수만을 사용하여 작업을 처리하는 경우도 있을 수 있다. 하지만 이것은 프로그램의 복잡도를 높여줄 수 있다. 뿐만 아니라 volatile 변수가 VM에서 정상적으로 동작하지 않는 경우 또한 보고된 적이 있기 때문에 주의를 요한다. 따라서 volatile변수를 사용하는것 대신 동기화를 사용하는 것을 권장한다.
참고자료.
1. http://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.7
17.7. Non-Atomic Treatment of double and long
For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
Writes and reads of volatile long and double values are always atomic.
Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
Some implementations may find it convenient to divide a single write action on a 64-bit long or double value into two write actions on adjacent 32-bit values. For efficiency's sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes to long and double values atomically or in two parts.
Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as volatile or synchronize their programs correctly to avoid possible complications.
------------------------------------------------------------------------------------------------------------------------------------------------------
정리 해보자...
멀티 스레딩과 멀티 코어를 대략적으로 이해하고 있다면 volatile 키워드를 훨씬 이해하기 수월하리라 생각한다.
결론부터 말하자면 volatile이 선언되어있는 변수(JDK1.5이상은 volatile 키워드를 가지고있는 해당 스레드 인스턴스의 전체 변수와 변수관계들)가 항상 최신의 상태의 값을 읽고 쓸수있게 해준다. 또한 자바에서 64bit연산의 읽고쓰기의 원자성을 보장 및 리오더링을(컴파일시 위치최적화) 방지한다.
멀티 쓰래드 어플리케이션에의 각 쓰래드들은 성능적이 이유로 공유 메인 메모리로 부터 변수를 읽어 CPU 캐시에 복사하고 작업하게되는데. 만약 컴퓨터가 하나 이상의 CPU로 구성되어있다면 각 쓰래드들이 서로 다른 CPU에서 실행 될수 있다. 이 말은 곧 각각의 쓰래드들이 서로 다른 CPU들의 CPU 캐시에 값을 복사할 수 있다는 말이고 각각 CPU 캐시의 값이 다를수도 있다는 말이된다. (1번째 블로그글 그림 참조) 그래서 volatile 키워드를 사용하면 항상 CPU들이 공유하고 있는 메인메모리 영역으로 읽고 쓰기때문에 데이터 가시성이 보장된다는 내용이다. 2번째 내용은 버전별 volatile 키워드가 다르게 동작하는것과 synchronized의 작업단위 동기화와의 차이점 그리고 내용추가에서 원자성에 대해서 언급이된다.
자바언어 명세상 long관 double 이외의 변수를 읽고 쓰는 동작은 원자적이다[JLS, 174, 1.7], JAVA 에서 64bit의 연산을 할때 non-volatile double, long은 원자성을 보장하지 않는다. (long or doublel value is treated as two separate writes: one to each 32-bit half.) (프로그램 언어와 하드웨어의 환경에 따라 차이가 있고(JVM 구현에따라 다를수있음) 요즘의 64bit JVM 환경 에서는 원자성을 보장한다는 말이있음.)
어쨌든 내용은.. 동기화를 하지않는 멀티스래드 환경에서 double, long 연산은 thread-safe 하지 않다는 말이다
동기화는 배타적 실행뿐 아니라 스레드 사이의 안정적인 통신에 꼭필요하다. 이는 한 스레드가 만든 변화가 다른 스레드에게 언제 어떻게 보이는지를 규정한 자바의 메모리 모델 때문이다.[JLS, 17.4; Goetz06, 16]
자바에서 동기화는 두가지 기능을 수행한다.
1. 배타적 수행
2. 스레드간 통신.
volatile 키워드는 synchronized 키워드처럼 (배타적 수행 + 스레드간 통신) 을 보장하지는 않고 오직 스레드간 통신만을 보장해준다.
스레드 로컬캐시를 읽어오는 것이아닌 항상 메인 메모리의 값을 읽어와 결국은 항상 가장 최근에 기록된값을 읽게 됨을 보장한다.
때문에 베타적 실행은 필요없고 스레드끼리의 통신만 필요하다면 성능에 이점을 보기위하여 volatile 한정자만으로 동기화 할수 있지만, 올바로 사용하기가 까다롭다.
가변 데이터는 단일 스레드에서만 쓰도록 한게 좋지만, 자바에서는 많은 동시성 라이브러리 (Atomic 관련 등)를 지원하기 때문에 잘찾아보고 활용하자.
'일하다가??' 카테고리의 다른 글
| OSX : NFS Mount (NFS 마운트) (0) | 2016.10.31 |
|---|---|
| 해시값의 복호화 ?? (18) | 2016.10.08 |
| 암호화 알고리즘 종류 (1) | 2016.10.08 |
| Servlet 이란? 서블릿 이란? (4) | 2016.05.12 |
| 자바 어노테이션 (Java Annotation) (0) | 2016.04.30 |


댓글